Understanding the Critical Role of Model Validation in Data Science
Written on
Chapter 1: The Necessity of Model Validation
In the realm of data science, one frequent dilemma arises: a machine learning model that appears successful during development may fail dramatically when deployed in a live environment. This situation often leads to skepticism from stakeholders regarding the efficacy of machine learning methodologies. But why does this discrepancy occur?
A primary reason for the gap between development outcomes and real-world performance is often attributed to the selection of an inadequate validation set—or, in some cases, the absence of a validation set altogether. The choice of validation set is critical and can significantly influence the model's effectiveness based on the characteristics of the dataset.
Our primary focus should not merely be on how well the model performs on training data. Instead, we must prioritize the accuracy of predictions made on previously unseen test data.
For instance, if we aim to create an algorithm that predicts stock prices based on historical returns, we might train our model using data from the past six months. However, what truly matters is the model's ability to forecast future prices, whether for tomorrow or next month, rather than its performance on past data.
Similarly, consider a scenario involving clinical measurements—such as weight, blood pressure, and family medical history—for various patients, along with their diabetes status. The goal is to develop a statistical learning method that accurately predicts diabetes risk for new patients based on these clinical indicators. The model's effectiveness in predicting outcomes for the training patients is less relevant since their statuses are already known.
Why is it essential to reserve an independent test set?
Hastie, Tibshirani, and Friedman provide an insightful explanation in their book, The Elements of Statistical Learning, particularly in Chapter 7, which deals with model assessment and selection. They recommend that in data-rich environments, the dataset should ideally be split into three segments: a training set, a validation set, and a test set. The training set is used for model fitting, the validation set for estimating prediction errors during model selection, and the test set for evaluating the generalization error of the final model. It is crucial to keep the test set separate until the analysis is complete, as repeated use can lead to an underestimation of the true test error.
Are there alternative methods for model validation beyond the train/test split?
Sebastian Raschka provides a comprehensive overview in his paper, Model Evaluation, Model Selection, and Algorithm Selection in Machine Learning, where he outlines four validation techniques:
- Performance estimation
- Two-way holdout method (train/test split)
- Repeated k-fold cross-validation without an independent test set
- Model selection (hyperparameter optimization) and performance estimation
- Three-way holdout method (train/validation/test split)
- Repeated k-fold cross-validation with an independent test set
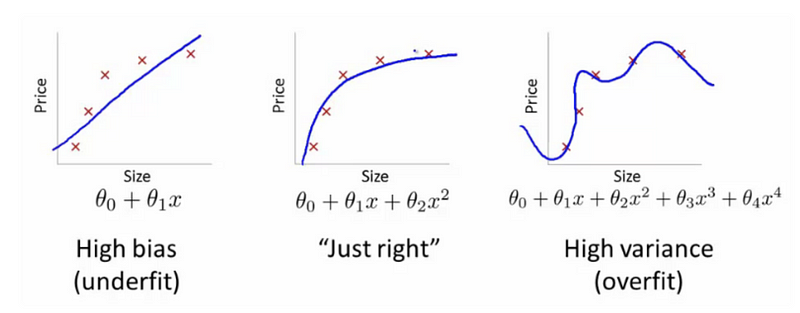
Chapter 2: Insights from Experts
In the video, "Validating Machine Learning Model and Avoiding Common Challenges," various experts discuss the significance of effective model validation, emphasizing strategies to circumvent typical pitfalls.
The second video, "Intro to Machine Learning Lesson 4: Model Validation | Kaggle," provides a foundational understanding of model validation techniques and their importance in machine learning.
Thanks for Reading!
If you found this article insightful, feel free to follow me on Medium for additional content. Your support helps bring these discussions to a wider audience. If you would like to continue receiving similar articles, consider subscribing to Medium.