Mastering Spring Batch in Spring Boot: A Comprehensive Guide
Written on
Introduction to Spring Batch
Spring Batch is an advanced framework tailored to assist developers in creating efficient batch processing applications. As part of the broader Spring ecosystem, it excels in handling substantial data volumes. Whether your task involves managing millions of database entries, processing extensive files, or executing long-running operations, Spring Batch equips you with the essential tools and infrastructure to streamline batch processing.
Before diving into this tutorial, ensure you have a grasp of basic Java programming and fundamental Spring Boot concepts.
Table of Contents:
- Understanding Batch Processing
- Overview of Spring Batch
- Setting Up a Spring Boot Batch Project
- Core Concepts of Spring Batch
- Configuring a Batch Job
- Running the Batch Job
- Detailed Look at JobLauncher
- Handling Job Restarts
- Managing Large Data with Chunk-Oriented Processing
- Parallel Processing Techniques in Spring Batch
What is Batch Processing?
Batch processing involves executing a series of jobs or tasks automatically, without the need for manual input. In contrast to real-time processing, where tasks are executed immediately, batch processing organizes large data sets into manageable chunks. Typically, these jobs are scheduled for execution during off-peak hours to optimize system performance.
Common applications of batch processing include:
- Data Migration: Moving data between databases.
- Report Generation: Compiling information from multiple sources into reports.
- Data Cleansing: Identifying and correcting errors in large datasets.
- ETL Processes: Extracting data from varied sources, transforming it per business requirements, and loading it into a target database.
Spring Batch enhances batch processing by providing reusable components like readers, processors, and writers, along with key features such as:
- Declarative I/O: Spring Batch includes various ItemReader and ItemWriter implementations for interacting with multiple data sources, simplifying the complexities of I/O operations.
- Transaction Management: The framework ensures data consistency through built-in transaction management, especially when interacting with databases.
- Chunk-Oriented Processing: This concept involves breaking down large datasets into smaller, manageable chunks for in-memory processing, followed by committing them in a single transaction.
- Parallel Processing: Spring Batch allows jobs to be segmented into smaller tasks that can operate concurrently, significantly improving performance for large-scale applications.
- Job Monitoring and Restartability: The framework provides tools for monitoring job execution, managing failures, and resuming jobs from their last successful state, ensuring effective management of lengthy jobs in production.
Setting Up a Spring Boot Batch Project
To embark on your Spring Batch journey, begin by creating a Spring Boot project using Spring Initializr or your preferred IDE. Include the following dependencies:
- Spring Batch
- Spring Boot DevTools (optional for development)
- Spring Data JPA (optional, if using JPA for persistence)
- H2 Database (optional, for in-memory database)
Here’s a sample pom.xml configuration:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
</dependency>
</dependencies>
Core Concepts of Spring Batch
Grasping the core concepts of Spring Batch is crucial as they form the foundation for batch processing:
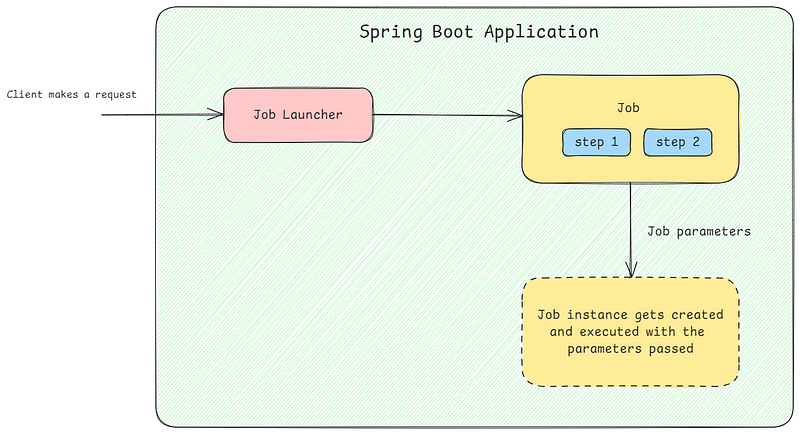
- Job: Represents the entire batch processing task, outlining the sequence of steps and control flow necessary to complete the process. Each job may contain multiple steps, dictating their order and execution conditions.
@Bean
public Job importUserJob(JobBuilderFactory jobBuilderFactory, Step step1, Step step2) {
return jobBuilderFactory.get("importUserJob")
.start(step1)
.next(step2)
.build();
}
- Step: Denotes a specific phase within a job, acting as its building block. Steps can be reused and combined in various configurations.
Types of Steps:
- Tasklet Step: Executes a straightforward task using a Tasklet.
- Chunk-Oriented Step: Processes items in batches via an ItemReader, ItemProcessor, and ItemWriter.
@Bean
public Step step1(StepBuilderFactory stepBuilderFactory, ItemReader<String> reader,
ItemProcessor<String, String> processor, ItemWriter<String> writer) {return stepBuilderFactory.get("step1")
.<String, String>chunk(10)
.reader(reader)
.processor(processor)
.writer(writer)
.build();
}
- Tasklet: Represents a single, atomic task within a step, suitable for simple operations like file handling or database maintenance.
@Bean
public Step taskletStep(StepBuilderFactory stepBuilderFactory) {
return stepBuilderFactory.get("taskletStep")
.tasklet((contribution, chunkContext) -> {
System.out.println("Executing Tasklet Step");
return RepeatStatus.FINISHED;
}).build();
}
- ItemReader: Responsible for retrieving data from a source, such as a file or database, item by item.
@Bean
public FlatFileItemReader<UserClass> csvReader() {
return new FlatFileItemReaderBuilder<UserClass>()
.name("csvReader")
.resource(new ClassPathResource("data.csv"))
.delimited()
.names("field1", "field2", "field3")
.targetType(UserClass.class)
.build();
}
- ItemProcessor: Processes or transforms the data obtained by the ItemReader, applying business logic or filtering before passing it to the ItemWriter.
@Bean
public ItemProcessor<UserClass, UserClass> csvProcessor() {
return item -> {
item.setField1(item.getField1().toUpperCase());
return item;
};
}
- ItemWriter: Responsible for outputting the processed data to a designated destination, such as a file or database.
@Bean
public ItemWriter<YourClass> csvWriter() {
return items -> {
for (YourClass item : items) {
System.out.println("Writing item: " + item);}
};
}
Configuring a Batch Job in Spring Batch
Spring Batch necessitates specific infrastructure components, including a JobRepository, JobLauncher, and TransactionManager, to operate effectively. These components handle job metadata, initiate jobs, and manage transactions.
Create a BatchConfig.java file in your source folder and integrate the following:
@Configuration
@EnableBatchProcessing
public class BatchConfig {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
public BatchConfig(JobBuilderFactory jobBuilderFactory, StepBuilderFactory stepBuilderFactory) {
this.jobBuilderFactory = jobBuilderFactory;
this.stepBuilderFactory = stepBuilderFactory;
}
@Bean
public JobLauncher jobLauncher(JobRepository jobRepository) {
SimpleJobLauncher jobLauncher = new SimpleJobLauncher();
jobLauncher.setJobRepository(jobRepository);
return jobLauncher;
}
@Bean
public JobRepository jobRepository(DataSource dataSource, PlatformTransactionManager transactionManager) {
JobRepositoryFactoryBean factory = new JobRepositoryFactoryBean();
factory.setDataSource(dataSource);
factory.setTransactionManager(transactionManager);
factory.setDatabaseType(DatabaseType.MYSQL.name());
return factory.getObject();
}
@Bean
public PlatformTransactionManager transactionManager(DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);}
}
- JobRepository: Stores job execution metadata, including status and parameters.
- JobLauncher: Initiates batch jobs and manages their execution.
- TransactionManager: Ensures transactional integrity across steps.
Defining a Job:
Now, define a Job in a new Java file as a Bean.
@Bean
public Job processJob(Step step1, Step step2) {
return jobBuilderFactory.get("processJob")
.start(step1)
.next(step2)
.build();
}
This job consists of two sequential steps (step1 and step2).
Configuring an ItemReader, ItemProcessor, and ItemWriter:
Spring Batch provides an array of built-in readers, like FlatFileItemReader for files and JdbcCursorItemReader for databases. Here’s how to configure one for CSV files:
@Bean
public FlatFileItemReader<String> itemReader() {
return new FlatFileItemReaderBuilder<String>()
.name("csvReader")
.resource(new ClassPathResource("data.csv"))
.delimited()
.names(new String[]{"column1", "column2"})
.fieldSetMapper(new BeanWrapperFieldSetMapper<>() {
{
setTargetType(String.class);}
}).build();
}
@Bean
public ItemProcessor<String, String> itemProcessor() {
return item -> {
return item.toUpperCase(); // Convert data to uppercase};
}
@Bean
public ItemWriter<String> itemWriter() {
return items -> {
for (String item : items) {
System.out.println("Writing item: " + item);}
};
}
Running the Batch Job:
Once your batch job and its components are set up, you can execute it as part of a Spring Boot application. The Spring Batch infrastructure will manage job execution, step processing, and transaction handling.
@SpringBootApplication
public class BatchApplication {
public static void main(String[] args) {
SpringApplication.run(BatchApplication.class, args);}
}
This functionality is facilitated by Inversion of Control and Dependency Injection through the @Bean annotation.
Configuring a Job Scheduler (Optional):
Batch jobs are often scheduled for execution at specific intervals. Spring Batch can be integrated with Spring’s @Scheduled annotation for automatic job execution.
@EnableScheduling
public class BatchScheduler {
private final JobLauncher jobLauncher;
private final Job processJob;
public BatchScheduler(JobLauncher jobLauncher, Job processJob) {
this.jobLauncher = jobLauncher;
this.processJob = processJob;
}
@Scheduled(cron = "0 0 12 * * ?") // Runs daily at noon
public void runJob() throws Exception {
JobParameters params = new JobParametersBuilder()
.addString("JobID", String.valueOf(System.currentTimeMillis()))
.toJobParameters();
jobLauncher.run(processJob, params);
}
}
The JobLauncher in Detail:
The JobLauncher interface in Spring Batch provides a mechanism to initiate a Job. It takes a Job and a set of JobParameters, returning a JobExecution object with execution details, such as status and timestamps.
The primary method in the JobLauncher interface is:
JobExecution run(Job job, JobParameters jobParameters) throws JobExecutionAlreadyRunningException,
JobRestartException, JobInstanceAlreadyCompleteException, JobParametersInvalidException;
- Job: The batch job to be executed.
- Job Parameters: Unique identifiers for job instances, essential for differentiating executions.
- JobExecution: Contains status and metadata for the executed job.
To utilize the JobLauncher, it must be configured as a Spring bean in your application context. Typically, Spring Batch’s SimpleJobLauncher implementation suffices.
@Configuration
@EnableBatchProcessing
public class BatchConfig {
private final JobRepository jobRepository;
private final PlatformTransactionManager transactionManager;
public BatchConfig(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
this.jobRepository = jobRepository;
this.transactionManager = transactionManager;
}
@Bean
public JobLauncher jobLauncher() throws Exception {
SimpleJobLauncher jobLauncher = new SimpleJobLauncher();
jobLauncher.setJobRepository(jobRepository);
jobLauncher.setTaskExecutor(new SimpleAsyncTaskExecutor()); // Optional: Run jobs asynchronously
jobLauncher.afterPropertiesSet();
return jobLauncher;
}
}
Once set up, the JobLauncher can trigger jobs programmatically, whether from a REST controller, a scheduled task, or any Spring-managed component.
Here’s an example of launching a job through a REST controller:
@RestController
public class JobController {
private final JobLauncher jobLauncher;
private final Job job;
public JobController(JobLauncher jobLauncher, Job job) {
this.jobLauncher = jobLauncher;
this.job = job;
}
@PostMapping("/run-job")
public ResponseEntity<String> runJob() {
try {
JobParameters jobParameters = new JobParametersBuilder()
.addString("JobID", String.valueOf(System.currentTimeMillis()))
.toJobParameters();
JobExecution jobExecution = jobLauncher.run(job, jobParameters);
return ResponseEntity.ok("Job executed successfully, status: " + jobExecution.getStatus());
} catch (Exception e) {
e.printStackTrace();
return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR).body("Job execution failed: " + e.getMessage());
}
}
}
Post-execution, the JobExecution object holds crucial job status information, including:
- Job Status: Indicates whether the job was successful, failed, or still running.
- Exit Status: Provides insights into the job’s termination condition.
- Job Instance ID: A unique identifier for the job instance.
- Start and End Time: Timestamps marking the job's start and end.
System.out.println("Job Execution ID: " + jobExecution.getId());
System.out.println("Job Status: " + jobExecution.getStatus());
System.out.println("Job Exit Status: " + jobExecution.getExitStatus().getExitCode());
System.out.println("Job Start Time: " + jobExecution.getStartTime());
System.out.println("Job End Time: " + jobExecution.getEndTime());
Handling Job Restarts
Spring Batch accommodates job restarts if a job fails or halts unexpectedly. The JobRepository tracks each job's execution state, enabling resumptions from the last successful step.
try {
JobExecution jobExecution = jobLauncher.run(job, jobParameters);
if (jobExecution.getStatus() == BatchStatus.FAILED) {
System.out.println("Job failed. Restarting...");
jobExecution = jobLauncher.run(job, jobParameters);
}
} catch (Exception e) {
e.printStackTrace();
}
BatchStatus.FAILED indicates a job failure, prompting a restart.
JobRepository monitors job progress, supporting resume capabilities.
Restartability Considerations: Ensure steps are idempotent, allowing them to run multiple times without negative consequences, while employing suitable job parameters for restart control.
Handling Large Data with Chunk-Oriented Processing
Chunk-oriented processing is pivotal for managing large datasets efficiently. Instead of processing all data simultaneously—which could be resource-intensive—this approach divides data into smaller, manageable chunks. Each chunk is read, processed, and written within a transaction, maintaining both efficiency and reliability.
This method is particularly beneficial when dealing with extensive datasets, like processing millions of records or large files, where loading everything into memory is impractical.
The workflow can be summarized as:
- Read: A chunk of items is obtained via an ItemReader.
- Process: Each item in the chunk is handled by an ItemProcessor.
- Write: The processed items are outputted using an ItemWriter.
For instance, if the chunk size is set to 10, ten items will be processed in a single transaction. Should an error occur during processing, only the current chunk will be rolled back, not the entire job.
To configure a chunk-oriented step in Spring Batch, define a Step that specifies the chunk size along with the ItemReader, ItemProcessor, and ItemWriter components.
@Configuration
@EnableBatchProcessing
public class BatchConfig {
@Bean
public Job job(JobBuilderFactory jobBuilderFactory, StepBuilderFactory stepBuilderFactory) {
return jobBuilderFactory.get("job")
.start(chunkStep(stepBuilderFactory))
.build();
}
@Bean
public Step chunkStep(StepBuilderFactory stepBuilderFactory) {
return stepBuilderFactory.get("chunkStep")
.<InputType, OutputType>chunk(10) // Define chunk size
.reader(itemReader())
.processor(itemProcessor())
.writer(itemWriter())
.build();
}
@Bean
public ItemReader<InputType> itemReader() {
return new CustomItemReader();}
@Bean
public ItemProcessor<InputType, OutputType> itemProcessor() {
return new CustomItemProcessor();}
@Bean
public ItemWriter<OutputType> itemWriter() {
return new CustomItemWriter();}
}
Parallel Processing in Spring Batch
Parallel processing in Spring Batch facilitates executing steps or chunks concurrently, greatly enhancing the performance of batch jobs that handle large datasets or require time-intensive operations. By distributing the workload across multiple threads or processes, overall execution time is significantly reduced.
Spring Batch provides several techniques for parallel processing:
- Multi-threaded Step: Allows a single step to be executed by multiple threads simultaneously. This is effective when the processing logic is thread-safe and the workload can be distributed.
@Bean
public Step multiThreadedStep(StepBuilderFactory stepBuilderFactory) {
return stepBuilderFactory.get("multiThreadedStep")
.<InputType, OutputType>chunk(10)
.reader(itemReader())
.processor(itemProcessor())
.writer(itemWriter())
.taskExecutor(taskExecutor()) // Enable multi-threading
.throttleLimit(4) // Limit concurrent threads
.build();
}
@Bean
public TaskExecutor taskExecutor() {
return new SimpleAsyncTaskExecutor();
}
- Partitioning: Divides data into smaller partitions, each processed by an independent thread or process, ideal for handling large datasets.
@Bean
public Step masterStep(StepBuilderFactory stepBuilderFactory, JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return stepBuilderFactory.get("masterStep")
.partitioner("slaveStep", partitioner())
.step(slaveStep(stepBuilderFactory))
.gridSize(4) // Number of partitions
.taskExecutor(taskExecutor())
.build();
}
@Bean
public Partitioner partitioner() {
return new CustomPartitioner(); // Defines partitioning logic
}
@Bean
public Step slaveStep(StepBuilderFactory stepBuilderFactory) {
return stepBuilderFactory.get("slaveStep")
.<InputType, OutputType>chunk(10)
.reader(itemReader())
.processor(itemProcessor())
.writer(itemWriter())
.build();
}
- Remote Chunking: Distributes reading and processing across multiple nodes while keeping writing centralized. This is advantageous when leveraging multiple machines for processing.
- Parallel Steps: Allows multiple steps within a job to execute concurrently, each operating independently without dependencies.
@Bean
public Job parallelJob(JobBuilderFactory jobBuilderFactory, Step step1, Step step2) {
return jobBuilderFactory.get("parallelJob")
.start(step1)
.split(taskExecutor())
.add(step2)
.build();
}
@Bean
public Step step1(StepBuilderFactory stepBuilderFactory) {
return stepBuilderFactory.get("step1")
.<InputType, OutputType>chunk(10)
.reader(itemReader1())
.processor(itemProcessor1())
.writer(itemWriter1())
.build();
}
@Bean
public Step step2(StepBuilderFactory stepBuilderFactory) {
return stepBuilderFactory.get("step2")
.<InputType, OutputType>chunk(10)
.reader(itemReader2())
.processor(itemProcessor2())
.writer(itemWriter2())
.build();
}
In this example, step1 and step2 are executed in parallel, utilizing the provided TaskExecutor. Each step can have its unique reader, processor, and writer, making it perfect for independent tasks, thus speeding up job execution.
Conclusion
In this guide, we have delved into the fundamentals of Spring Batch and its integration within Spring Boot applications for efficient batch processing. Whether you're managing extensive datasets, complex processing logic, or require reliable job execution, Spring Batch offers the necessary tools and flexibility to meet your needs.
This tutorial serves as a foundational stepping stone for building and refining batch processing solutions in your projects. There is much more to explore about Spring Batch; consider delving deeper into its features and functionalities.
I’ll never see them again. I know that. And they know that. And knowing this, we say farewell.
? Haruki Murakami, Kafka on the Shore
Explore the basics of Spring Batch in this detailed video tutorial.
Join the Spring Office Hours to learn about batch processing with Spring.