Exploring Llama 2: A Comprehensive Guide to Installation
Written on
Getting Started with Llama 2
How can you effectively use Hugging Face to implement Llama 2 on your own machine? While the process isn't overly complex, it does have its challenges.
Meta's recently open-sourced Llama 2 Chat model has garnered significant attention on the OpenLLMs Leaderboard. This robust language model is now accessible for anyone, including commercial use. Intrigued by this, I set out to implement Llama 2 myself. Although the steps were generally clear, I had to navigate through some hurdles to get everything up and running.
In this article, I will outline the process I followed to successfully set up Llama 2. With Meta increasingly open-sourcing their AI technologies, now is an exciting time to explore advanced language models!
Let’s dive into the necessary steps for running the Llama 2 Chat Model.
Obtaining Access
Securing access from both Meta and Hugging Face allowed me to easily fetch the latest version of Llama 2 for experimentation. The approval process typically takes a few hours, after which you’re ready to start!
Once I had access, I ran the following code:
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-13b-chat-hf") model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-13b-chat-hf")
However, I encountered authentication errors since the Meta repository is private. This meant I needed an authentication token, which wasn't immediately obvious to find.
Obtaining the Authentication Token
If you're planning to run your model on custom GPU machines hosted on AWS, GCP, or locally, you will need a Hugging Face token. This can be acquired by navigating to Settings > Access Tokens.
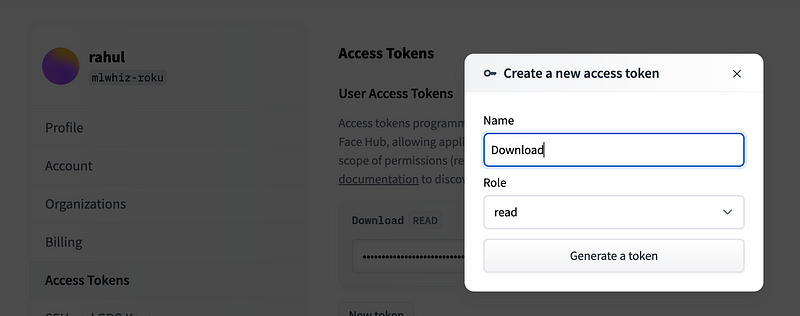
Once you have your token, installing it in your operating system's environment is quite straightforward. Open your terminal and execute:
pip install huggingface_hub
After the installation, you can log into Hugging Face using:
huggingface-cli login
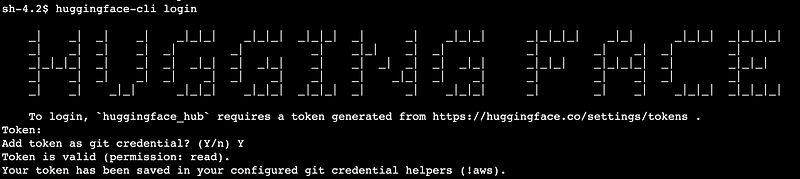
And that's it! You are now set to proceed.
Downloading the Models
To download the models, simply go to your Python Notebook and run:
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-13b-chat-hf", use_auth_token=True) model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-13b-chat-hf", use_auth_token=True, device_map='auto')
Next, you can set up a prompt like so:
prompt = "Hi, How are You?" inputs = tokenizer(prompt, return_tensors="pt").to("cuda") outputs = model.generate(inputs, max_new_tokens=20) response = tokenizer.decode(outputs[0], skip_special_tokens=True)
The device_map='auto' option automatically distributes the model across your available hardware in a priority order: GPU(s) > CPU (RAM) > Disk. For instance, if you have two GPUs, the model will be divided evenly between them.
And there you have it—you're now using the Llama 2 chat model!
Initial Comparisons
I experimented with both Llama-2 and Claude-2. While a direct comparison is challenging due to their different architectures and sizes, I was pleasantly surprised by Llama-2’s performance. Llama-2 is an open-source model with 13 billion parameters, whereas Claude-2 is one of the most advanced proprietary language models on the market. Despite Claude-2 having access to more extensive resources and data, Llama-2 held its ground and performed admirably on various tasks. Below are some of the tasks I tested:

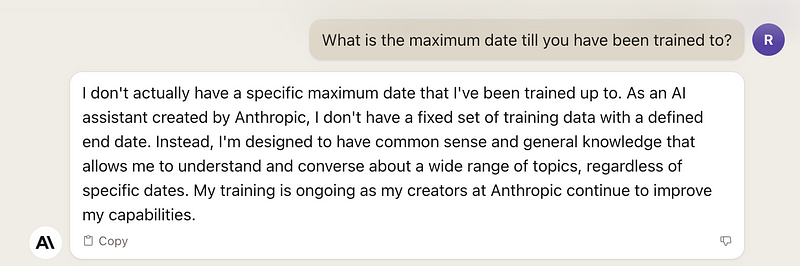
Regarding training data, it's worth noting that Llama has data available until the end of 2022, while Claude-2 keeps its training data more confidential.
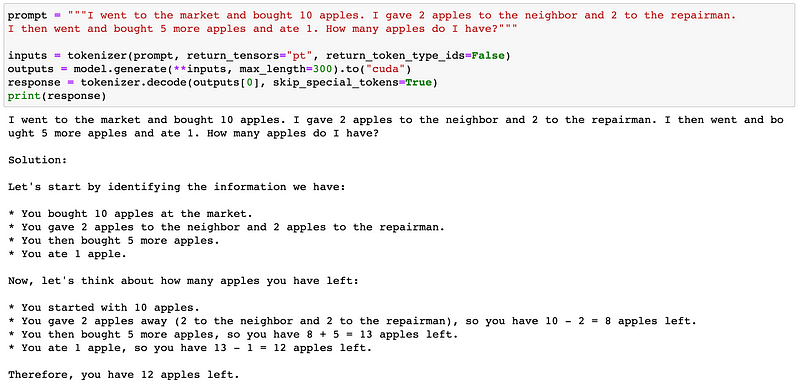
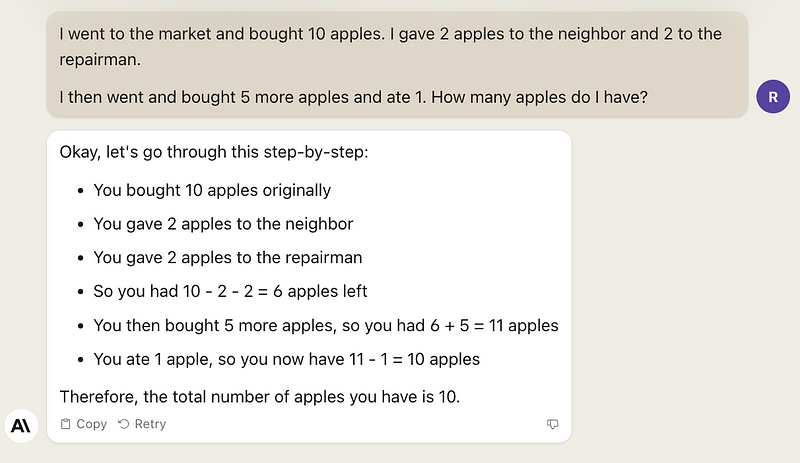
I found that Llama-2 struggles with mathematical comprehension, making mistakes more frequently compared to Claude-2.
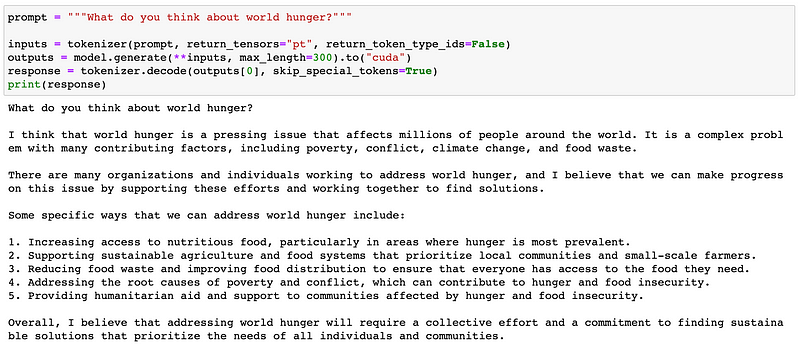
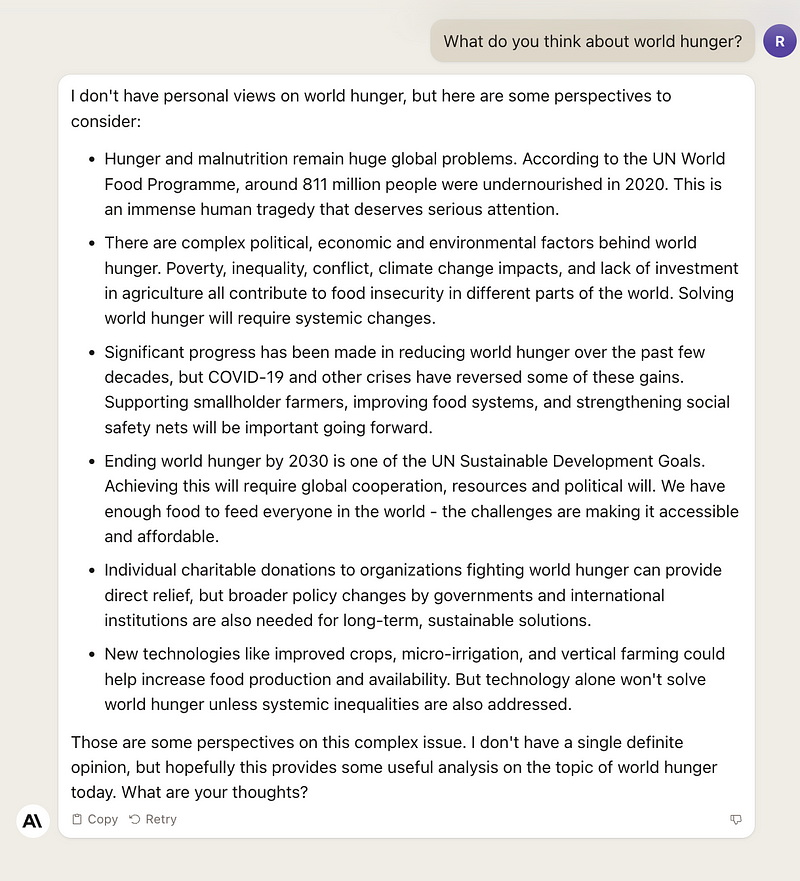
Although Llama-2 tends to be more opinionated, it's hard to determine which model is superior. The response I received from Llama-2 felt more subjective, while Claude-2 provided factual information, which may reflect differences in their training methodologies. Should language models express opinions?
Conclusion
With Meta's decision to open-source Llama 2, we now have access to a formidable conversational AI model with 13 billion parameters. While setting up Llama 2 involves navigating a few steps to gain access from Meta and Hugging Face, the implementation itself is quite straightforward with Transformers and PyTorch. You can easily load Llama 2 onto your hardware with just a few lines of code.
In my preliminary tests, Llama 2 competes well against proprietary models like Claude-2, despite having fewer parameters. Its performance across various tasks is quite commendable, although it often leans towards more opinionated responses. It will be exciting to see how the community leverages these powerful language models.
For those interested in delving deeper into LLMs and ChatGPT, I highly recommend the course "Generative AI with Large Language Models" from Deeplearning.ai. This course covers techniques like RLHF, Proximal Policy Optimization (PPO), as well as zero-shot, one-shot, and few-shot learning with LLMs, providing hands-on practice with these concepts. Be sure to check it out!
Also, please note that this post may contain affiliate links to related resources, as sharing knowledge is always beneficial.
Learning Llama 2: Beginner's Tutorial
The first video provides a beginner-friendly tutorial on using Llama 2 with Hugging Face's pipeline, complete with code examples in Colab.
Setting Up Llama 2 Locally
The second video offers a detailed step-by-step guide for setting up and running the Llama-2 model locally.